Prof. Dr.-Ing. Johannes Schildgen
johannes.schildgen@oth-regensburg.de
Datenbanken
Kapitel 6: Anwendungsentwicklung
2020-12-22


In diesem Kapitel erstellen wir...
- ... Java-Anwendungen, die mit JDBC mit der Datenbank kommunizieren,
- ... Funktionen und Prozeduren direkt in der Datenbank,
- ... Trigger,
- ... Indexe.
Anwendungsentwicklung
- Lauffähige Anwendung in Java, C++, Python, PHP, ...
- Konsolenprogramm, GUI, App, Serverprozess, ...
- Komponenten:
- Connection (Aufbau einer Verbindung zur DB)
- Statement (Ausführung einer SQL-Anfrage)
- PreparedStatement (Statement mit Platzhaltern)
- ResultSet (Ergebnis einer ausgeführten Anfrage)
Anwendung
Datenbank
Beispielanwendungen

Anwendungsserver
Java EE, JSP, Java Servlets, .NET, PHP, Django, ...
Endanwendung (z. B. Webbrowser) → Anwendungsserver → Datenbank
Embedded SQL
Ansatz: SQL-Anfragen und Programmcode mischen,
dann erzeugt ein Precompiler das eigentliche lauffähige Programm.
Beispiel: SQL Object-Language Bindings (OLB) für Java (vormals SQLJ)
ProdukteIterator iter;
#sql iter = { SELECT bezeichnung, preis FROM produkte };
do {
#sql { FETCH :iter INTO :bezeichnung, :preis };
System.out.println(bezeichnung+" kostet "+preis+" EUR");
} while (!iter.endFetch());
iter.close();Vorteil: Syntaxüberprüfung der Anfrage und Prüfung auf gültige Tabellen- und Spaltennamen kann bereits bei der Compile-Zeit erfolgen.
JDBC
SQL-Anfragen werden API-Methoden als Strings übergeben.
Vorteile: Flexibel (Anfragen können dynamisch zur Laufzeit generiert werden), kein Precompiler nötig, kompatibel mit allen Java-IDEs und vielen Frameworks.
Driver
Jedes DBMS hat seinen eigenen JDBC-Treiber: MySQL, PostgreSQL, Oracle, ...
⇒ Entsprechende Jar herunterladen und dem Java-Projekt zur Verfügung stellen
Nun kann über die Klasse DriverManager eine Verbindung aufgebaut werden.
Connection
Statement und ResultSet
SQL-Injections
Vorsicht beim Erzeugen von Query-Strings,
die Benutzereingaben beinhalten! (→ xkcd.com/327)
Geben Sie einen Hersteller ein:
SQL-Injections
Anderes Beispiel: Login-Formular
| E-Mail: | |
| Passwort: | |
PreparedStatement
Ein PreparedStatement beinhaltet ?-Platzhalter, die vor der Ausführung der Anfrage mit ihren Werten belegt werden.
Vorteile: Verhindert SQL SQL-Injections, weniger fehleranfällig, Wiederverwenden von Anfragen, Sonderzeichen (z. B. ') werden automatisch maskiert.
executeUpdate
DB-Metadaten-Zugriff mit JDBC
DatabaseMetaData
ResultSetMetaData
Routinen
Benutzerdefinierte Routinen sind in der DB gespeicherte Datenbankobjekte (wie Tabellen und Views):
- Prozeduren tun etwas
- Funktionen (UDF) liefern einen Ergebniswert
- Tabellenfunktionen liefern eine Tabelle
- Methoden gehören zu einem User-defined Datatype
Routen haben einen Namen und Eingabeparameter.
PL/pgSQL
Block:
[ DECLARE
-- hier können Variablen definiert werden ]
BEGIN
-- Anweisungen ...
END
Kontrollstrukturen:
IF ... THEN ... [ELSE ...] END IF;
WHILE ... LOOP ... END LOOP;
LOOP ... EXIT WHEN ...; END LOOP;
FOR ... IN ... .. ... LOOP ... END LOOP;
FOR ... IN 'SELECT ...' LOOP ... END LOOP;
Stored Procedures
CREATE OR REPLACE FUNCTION alles_leeren() RETURNS void AS
$$ BEGIN
TRUNCATE bewertungen CASCADE;
TRUNCATE produkte CASCADE;
TRUNCATE hersteller CASCADE;
TRUNCATE kunden CASCADE;
END $$ LANGUAGE plpgsql;SELECT alles_leeren();RAISE NOTICE
RAISE NOTICE gibt einen Infotext auf der Konsole aus.
CREATE OR REPLACE FUNCTION hallo() RETURNS void AS $$
DECLARE
x INT := 5;
BEGIN
RAISE NOTICE 'Hallo!!!';
RAISE NOTICE 'x ist %', x;
END $$ LANGUAGE plpgsql;SELECT hallo();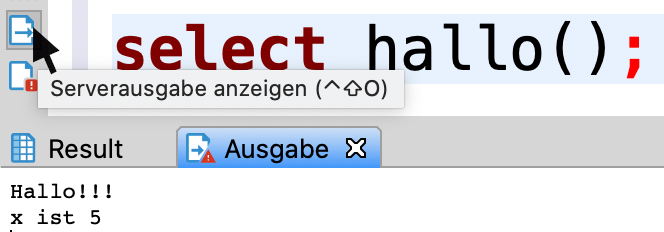
Stored Procedures
CREATE PROCEDURE bestelle_produkt(_kundennr INT,
_produktnr INT) AS $$
DECLARE
_bestellnr INT;
BEGIN
SELECT MAX(bestellnummer)+1 INTO _bestellnr FROM bestellungen;
RAISE NOTICE 'Bestellnummer: %', _bestellnr;
INSERT INTO bestellungen(bestellnummer, kundennummer, zeit,
preis) VALUES (_bestellnr, _kundennr, current_timestamp,
(SELECT preis FROM produkte WHERE produktnr=_produktnr));
INSERT INTO bestellungen_positionen (bestellnummer,
produktnummer, anzahl) VALUES (_bestellnr, _produktnr, 1);
COMMIT;
END $$ LANGUAGE plpgsql;CALL bestelle_produkt(5, 17);Eingabeparameter
Zugriff über den Namen oder die Position ($1, ...)
CREATE OR REPLACE PROCEDURE test(i int, s VARCHAR) AS $$
BEGIN
RAISE NOTICE 'i ist %', i; -- i ist 99
RAISE NOTICE 's ist %', $2; -- s ist Tomate
END $$ LANGUAGE plpgsql;CALL test(99, 'Tomate');Funktionen
UDF = User-defined Function
CREATE OR REPLACE FUNCTION addieren(int, int) RETURNS INT AS
$$ BEGIN RETURN $1+$2; END $$ LANGUAGE plpgsql;Wie lässt sich diese UDF aufrufen?
- EXECUTE addieren(5,4);
- SELECT addieren(5,4);
- SELECT * FROM addieren(5,4);
- CALL addieren(5,4);
https://frage.space
SELECT addieren(5,4);SELECT *, addieren(sterne, 1) FROM bewertungen;Exceptions werfen und behandeln
CREATE FUNCTION dividieren(float, float) RETURNS float AS
$$ BEGIN
RETURN $1/$2;
EXCEPTION WHEN OTHERS THEN
RAISE EXCEPTION 'Divisor darf nicht 0 sein!';
END $$ LANGUAGE plpgsql;Wo wird die "Divisor darf nicht 0 sein"-Exception angezeigt?
- Als Fehlermeldung anstelle des Query-Ergebnisses
- In der Serverausgabe (wie bei RAISE NOTICE)
- In der Query-Ergebnistabelle
- Nirgendwo
https://frage.space
Volatilitäts-Kategorien
CREATE OR REPLACE FUNCTION addieren(int, int) RETURNS INT AS
$$ BEGIN RETURN $1+$2; END $$ LANGUAGE plpgsql IMMUTABLE;VOLATILE (Standard)
Funktion darf alles: DB verändern und bei gleichen Parameterwerten unterschiedliche Ergebnisse liefern.
STABLE
Funktion darf die DB nicht verändern und muss innerhalb des gleichen Statements bei gleichen Parameterwerten das gleiche Ergebnis liefern.
IMMUTABLE
Funktion darf die DB nicht verändern und muss bei gleichen Parameterwerten das gleiche Ergebnis liefern.
Warum ergbit es Sinn, die addieren-UDF als IMMUTABLE zu kenzeichnen?
- Weil die UDF die Datenbank nicht verändert
- Weil die UDF nichts aus der Datenbank liest
- Weil die UDF nachträglich nicht mehr verändert wird
- Weil 1+1 immer 2 ist und so
https://frage.space
Tabellenfunktionen
CREATE OR REPLACE FUNCTION produkte_von(VARCHAR) RETURNS TABLE
(produktnr INT, bezeichnung VARCHAR(100),
preis DECIMAL(9,2), hersteller VARCHAR(50)) AS $$
SELECT produktnr, bezeichnung, preis, hersteller
FROM produkte WHERE hersteller = $1
$$ LANGUAGE sql;
Wie lässt sich diese Tabellenfunktion aufrufen?
- EXECUTE produkte_von('Calgonte');
- SELECT produkte_von('Calgonte');
- SELECT * FROM produkte_von('Calgonte');
- CALL produkte_von('Calgonte');
https://frage.space
SELECT * FROM produkte_von('Calgonte');Trigger
Wenn ...
- BEFORE
- AFTER
- INSTEAD OF
- INSERT
- UPDATE
- DELETE
- ON <tabelle>
- ON <view>
dann ...
Wann könnte BEFORE INSERT ON produkte sinnvoll sein (im Vergleich zu AFTER INSERT ON produkte)?
- Wenn man das INSERT doch noch ablehnen will
- Wenn man den nicht-vorhandenen Hersteller in die Hersteller-Tabelle einfügen will
- Wenn man die eingefügte Zeile noch modifizieren will
- Das macht gar keinen Unterschied
https://frage.space
Trigger in PostgreSQL
Triggerfunktion
- Definiert die auszuführende Aktion
CREATE FUNCTION ... RETURNS TRIGGER ...
Trigger
- Definiert den eigentlichen Trigger (die Wenn-Falls-Dann-Bedingung)
CREATE TRIGGER ... {BEFORE | AFTER | INSTEAD OF}
{INSERT | UPDATE | DELETE} ON ...
FOR EACH {ROW | STATEMENT} [WHEN (...)]
EXECUTE PROCEDURE ...();
AFTER INSERT
Nachdem das neue Tupel eingefügt wurde, soll noch etwas gemacht werden.
CREATE FUNCTION produkte_trigger() RETURNS TRIGGER AS
$$ BEGIN
IF (NEW.hersteller IS NOT NULL AND NOT EXISTS
(SELECT * FROM hersteller WHERE firma = NEW.hersteller)) THEN
INSERT INTO hersteller (firma) VALUES(NEW.hersteller);
END IF;
RETURN NEW;
END; $$ LANGUAGE plpgsql;NEW bietet Zugriff auf die neu eingefügte Zeile.
CREATE TRIGGER produkte_trigger AFTER INSERT ON produkte
FOR EACH ROW EXECUTE PROCEDURE produkte_trigger();AFTER INSERT
INSERT INTO produkte VALUES(1000, 'Kuchen', 2.00, 'Kuchenpeter');
[23503]: ERROR: insert or update on table "produkte" violates foreign key constraint "produkte_hersteller_fkey" Detail: Key (hersteller)=(Kuchenpeter) is not present in table "hersteller".
- Entweder Trigger auf
BEFORE INSERTändern - oder das Fremdschlüssel-Constraint auf
DEFERREDsetzen:
ALTER TABLE webshop.produkte ADD CONSTRAINT
produkte_hersteller_fkey FOREIGN KEY (hersteller)
REFERENCES hersteller(firma) ON UPDATE CASCADE
INITIALLY DEFERRED;BEFORE INSERT / UPDATE / DELETE
Mit einem BEFORE-Trigger kann man das einzufügende Tupel modifizieren oder das INSERT / UPDATE / DELETE ablehnen.
CREATE OR REPLACE FUNCTION preis_trigger() RETURNS TRIGGER AS $$
DECLARE anz_gratis_produkte INT;
BEGIN
IF (NEW.preis < 0) THEN NEW.preis = 0; END IF;
SELECT COUNT(*) INTO anz_gratis_produkte
FROM produkte WHERE preis = 0;
IF (NEW.preis = 0 AND anz_gratis_produkte >= 3) THEN
RAISE EXCEPTION 'Zu viele kostenlose Produkte!';
END IF;
RETURN NEW;
END; $$ LANGUAGE plpgsql;
CREATE TRIGGER preis_trigger BEFORE INSERT OR UPDATE ON produkte
FOR EACH ROW EXECUTE PROCEDURE preis_trigger();Könnte ein AFTER INSERT Trigger das INSERT auch noch ablehnen?
- Na klar
- Nein, dafür ist es zu spät
https://frage.space
OLD / NEW
INSERT-Trigger: Zugriff aufNEWDELETE-Trigger: Zugriff aufOLDUPDATE-Trigger: Zugriff aufOLDundNEW
CREATE OR REPLACE FUNCTION preiserhoehung_trigger()
RETURNS TRIGGER AS $$
BEGIN
IF (NEW.preis > OLD.preis*1.1) THEN
RAISE EXCEPTION 'Preiserhöhung um mehr als 10%% nicht erlaubt!';
END IF;
RETURN NEW;
END; $$ LANGUAGE plpgsql;FOR EACH ROW / STATEMENT
FOR EACH ROW
- Triggerfunktion wird für jedes eingefügte / gelöschte / geänderte Tupel einmal aufgerufen
- Zugriff auf das Tupel mittels
NEWbzw.OLD
FOR EACH STATEMENT
- Triggerfunktion wird für das gesamte INSERT / UPDATE / DELETE-Statement nur einmal aufgerufen
- Kein direkter Zugriff auf die Tupel
INSTEAD OF-Trigger
INSERT INTO meine_view VALUES (...)- Nur in simple Views Projektion-Selektion-Views darf ein INSERT/UPDATE/DELETE erfolgen
- Mittels einer
CHECK OPTIONkann überprüft werden, dass das Tupel auch das WHERE-Prädikat der View erfüllt. INSTEAD OF-Trigger ermöglichen INSERT/UPDATE/DELETE auf jeder View.
CREATE TRIGGER meine_view_trigger INSTEAD OF INSERT ON meine_view
FOR EACH ROW EXECUTE PROCEDURE meine_view_trigger();
INSTEAD OF-Trigger
CREATE VIEW meine_view AS
SELECT p.produktnr, p.bezeichnung, p.preis, p.hersteller, h.land
FROM produkte p JOIN hersteller h ON p.hersteller=h.firma;
CREATE OR REPLACE FUNCTION meine_view_trigger()
RETURNS TRIGGER AS $$
BEGIN
INSERT INTO hersteller (firma, land)
VALUES (NEW.hersteller, NEW.land)
ON CONFLICT (firma) DO UPDATE SET land=EXCLUDED.land;
INSERT INTO produkte (produktnr, bezeichnung, preis, hersteller)
VALUES (NEW.produktnr, NEW.bezeichnung, NEW.preis, NEW.hersteller);
RETURN NEW;
END; $$ LANGUAGE plpgsql;Indexe
Motivation: Wir haben $n$ Produkte. Wie teuer ist die folgende Anfrage?
SELECT * FROM produkte WHERE produktnr = 29- Full Table Scan: $O(n)$
- Tabelle intern sortiert nach Produktnummer: $O(log_2(n))$
- B-Baum-Index auf der Produktnummer: $O(log_k(n))$
- Hash-Index auf der Produktnummer: $O(1)$
Full Table Scan
Linearer Aufwand: $O(n)$
Jede einzelne Zeile wird gelesen und für sie wird überprüft, ob das WHERE-Prädikat wahr oder falsch ist.
SELECT * FROM produkte WHERE produktnr = 29Clustered Index
Logarithmischer Aufwand: $O(log_2(n))$
Binäre Suche: In die Mitte der Tabelle springen. Hat diese Zeile eine größere Produktnummer als die gesuchte? Oberhalb weitersuchen, usw.
CLUSTER produkte USING produkte_pkeySELECT * FROM produkte WHERE produktnr = 29- Es kann nur einen Clustered Index pro Tabelle geben
- Re-Clustering nötig nach INSERT, UPDATE, DELETE
B-Bäume
Logarithmischer Aufwand: $O(log_k(n))$
Simulation: https://www.cs.usfca.edu/~galles/visualization/BTree.html
- Jeder Knoten hat maximal den Grad 2k+1,
also max. 2k+1 Kindknoten - Jeder Knoten speichert zw. k und 2k Einträge
- Suche startet in der Wurzel,
dann wird sich durch den Baum navigiert:
kleiner: links; größer: rechts entlang
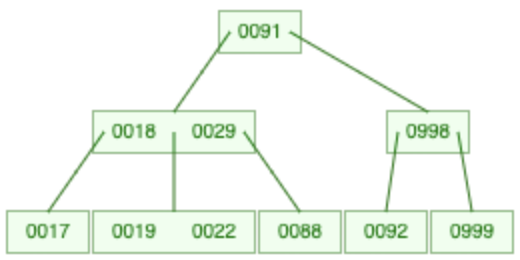
k=1 ⇒ max. Grad = 3
B+-Bäume
Simulation: https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
- Optimierung des B-Baums; in DMBS häufigst eingesetzte Indexstruktur
- Innere Knoten sind nur Wegweiser (max. 2k Schlüssel, max. 2k+1 Kinder)
- Blattknoten enthalten die Schlüssel und Pointer zu max. 2k*+1 Datensätzen
- Blattknoten sind miteinander verkettet ⇒ schnelle sequenzielle Suche
- Suche startet in der Wurzel, dann links (<) oder rechts (≥) weitersuchen
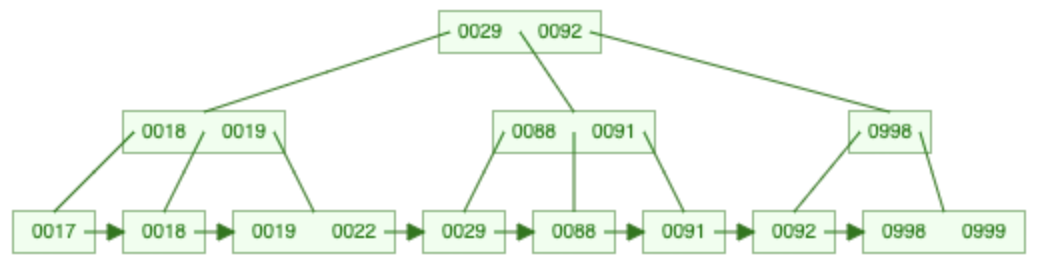
k=1, k*=1 ⇒ max. Grad = 3
Einfügen in B+-Baum
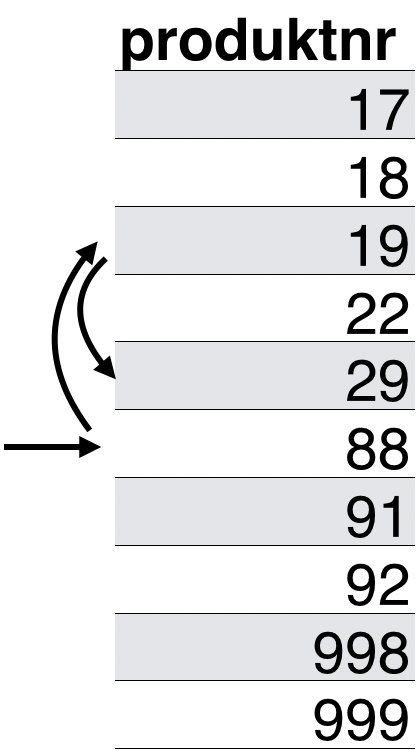
- Blattknoten suchen, in welchen der neue Schlüssel gehört
- Noch Platz? ⇒ einfach einfügen
18 einfügen
→
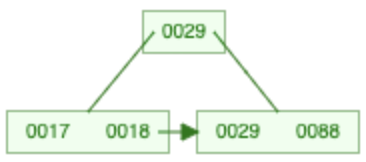
Einfügen in B+-Baum
- Blattknoten suchen, in welchen der neue Schlüssel gehört
- Noch Platz? ⇒ einfach einfügen
- Kein Platz mehr? ⇒ einfügen und Knoten splitten
Split
- Knoten wird in zwei Knoten aufgesplittet
- Mittleres Element wandert zusätzlich als Wegweiser in Vaterknoten
- Evtl. ist dort ebenfalls ein Split nötig, wenn er voll ist
22 einfügen
→
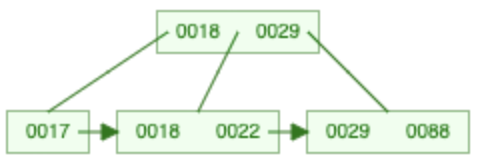
Einfügen in B+-Baum
998 einfügen
→
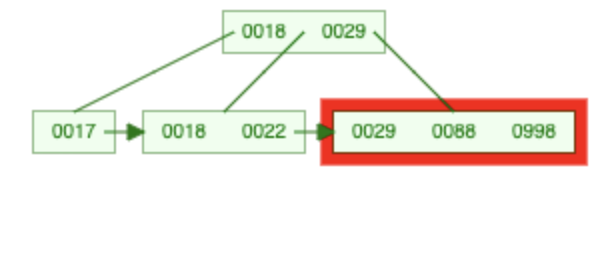
→
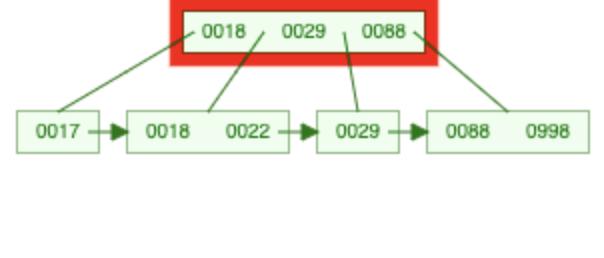
→
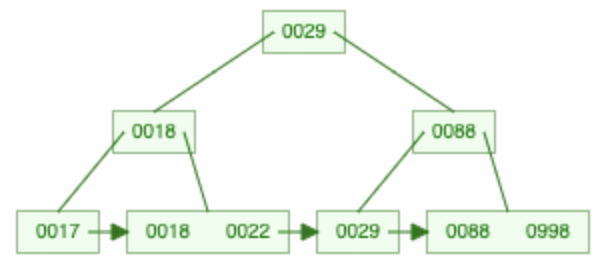
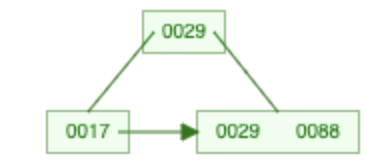
Löschen im B+-Baum
- Blattknoten suchen, in welchem sich der zu löschende Schlüssel befindet
- Danach noch mind. k* Einträge? ⇒ einfach löschen
998 löschen
→
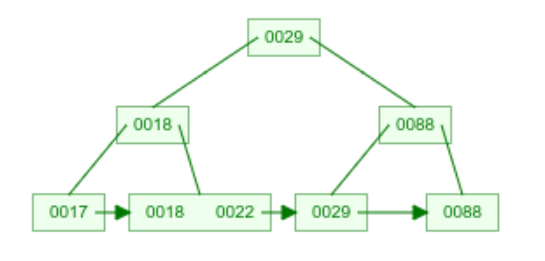
Löschen im B+-Baum
- Blattknoten suchen, in welchem sich der zu löschende Schlüssel befindet
- Danach noch mind. k* Einträge? ⇒ einfach löschen
- Unterlauf ⇒ mit dem Nachbarknoten ausgleichen oder mischen
Ausgleich
- Einträge vom Nachbarknoten übernehmen zum Ausgleichen
- Wegweiser im Vaterknoten entsprechend anpassen
29 löschen
→
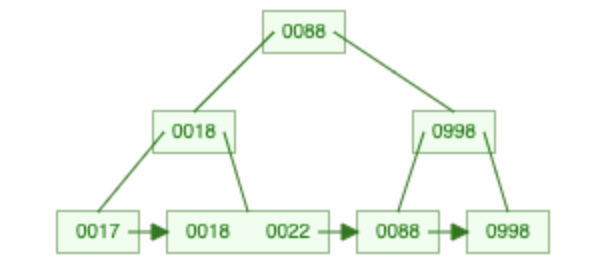
Löschen im B+-Baum
- Blattknoten suchen, in welchem sich der zu löschende Schlüssel befindet
- Danach noch mind. k* Einträge? ⇒ einfach löschen
- Unterlauf ⇒ mit dem linken Nachbarknoten ausgleichen oder mischen
Mischen (Merge)
- Falls Nachbarknoten auch unterlaufen würden ⇒ mischen
- Wegweiser aus dem Vater entfernen
- Evtl. ist dort ebenfalls ein Ausgleich / Merge nötig
998 löschen
→
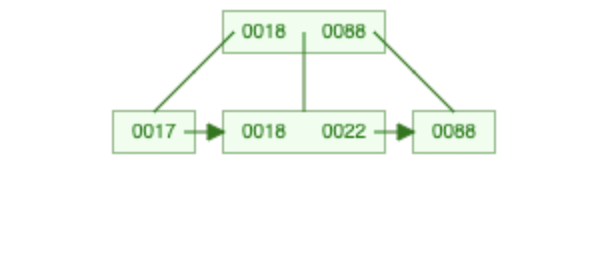
CREATE INDEX
CREATE INDEX erstellt in den meisten DBMS einen B+-Baum-Index.
CREATE INDEX produkte_pkey ON produkte(produktnr);Kosten
- Bei INSERT, UPDATE, DELETE muss der Index entsprechend gepflegt werden
Nutzen
- Schnellere exakte Suche (
=) und Bereichssuche (<,<=,>,>=,BETWEEN) - Index kann auch bei
ORDER BY,GROUP BYund Joins helfen.
Die meisten DBMS legen Indexe auf Primärschlüsselspalten automatisch an.
Weitere Indexe müssen manuell angelegt werden.
Mehrdimensionale Indexe
CREATE INDEX ON meine_tabelle(a, b, c);Kann genutzt werden bei:
WHERE a = 5 AND b = 7 AND c = 2WHERE a = 5 AND b = 7WHERE a = 5- Bei B+-Baum-Indexen auch bei
<,<=,>,>=,BETWEEN,LIKE '...%'
Join-Algorithmen
SELECT * FROM produkte p JOIN hersteller h
ON p.hersteller=h.firma;Es gibt viele Arten, einen Join auszuführen:
- Nested-Loop-Join: Für jede Zeile der ersten Tabelle wird mit jeder Zeile der zweiten Tabelle überprüft, ob das Join-Prädikat wahr ist.
- Sort-Merge-Join: Beide Tabellen werden nach der Join-Spalte sortiert, dann beide von oben nach unten durchgescannt, um Join-Partner zu suchen.
- Hash-Join: Hash-Tabelle wird für kleinere Tabelle angelegt, dann die größere Tabelle durchlaufen und Join-Partner mittels der Hash-Tabelle gesucht.
- Index-Join: Während eine Tabelle komplett durchlaufen wird, werden für jede Zeile die Join-Partner in der anderen Tabelle mittels eines Indexes gesucht.
Nested-Loop-Join
SELECT * FROM produkte p JOIN hersteller h
ON p.hersteller=h.firma;Für jede Zeile der ersten Tabelle $R$ wird mit jeder Zeile der zweiten Tabelle $S$
überprüft, ob das Join-Prädikat wahr ist.
for each row p in PRODUKTE:
for each row h in HERSTELLER:
if p.hersteller == h.firma:
emit(p, h)Aufwand: $O(|R|\cdot|S|)$
Sort-Merge-Join
SELECT * FROM produkte p JOIN hersteller h
ON p.hersteller=h.firma;Beide Tabellen werden nach der Join-Spalte sortiert, dann beide von oben nach unten durchgescannt, um Join-Partner zu suchen.
Aufwand: $O(|R|\cdot log(|R|) + |S|\cdot log(|S|))$
Hash-Join
SELECT * FROM produkte p JOIN hersteller h
ON p.hersteller=h.firma;Hash-Tabelle wird für kleinere Tabelle angelegt, dann die größere Tabelle durchlaufen und Join-Partner mittels der Hash-Tabelle gesucht.
hash_tabelle = []
for each row h in HERSTELLER:
hash_tabelle.put(hash(h.firma)), h)
for each row p in PRODUKTE:
h = hash_tabelle.get(hash(p.hersteller))
emit(p, h)Aufwand: $O(|R|+|S|)$
Index-Join
SELECT * FROM produkte p JOIN hersteller h
ON p.hersteller=h.firma;Während eine Tabelle komplett durchlaufen wird, werden für jede Zeile die Join-Partner in der anderen Tabelle mittels eines Indexes gesucht.
for each row p in PRODUKTE:
h = hersteller_firma_idx.get(p.firma)
emit(p, h)Aufwand hängt von den Index-Kosten ab, z. B. $O(|R|\cdot log(|S|))$, wenn es einen B+-Baum-Index auf S gibt, oder $O(|R|)$, wenn ein Hash-Index existiert.
Kapitelzusammenfassung
- DB-Anwendungen: Embedded SQL, JDBC
- JDBC: DriverManager, Connection, Statement, PreparedStatement, ResultSet
- SQL-Injections
- Benutzerdefinierte Routinen: Stored Procedures, (Tabellen-)Funktionen
- Trigger: BEFORE / AFTER / INSTEAD OF
- Indexe: Clustered Index, B-Baum, B+-Baum
- Join-Algorithmen: Nested-Loop-Join, Sort-Merge-Join, Hash-Join, Index-Join